Important
La traduction est le fruit d’un effort communautaire auquel vous pouvez vous joindre. Cette page est actuellement traduite à 100.00%.
17.22. Interpolation
Note
Ce chapitre explique comment interpoler des données points et présente un autre exemple concret d’utilisation de l’analyse spatiale.
Dans cette leçon, nous allons interpoler des points afin d’obtenir une couche raster. Avant de le faire, nous devons préparer les données. Nous modifierons également la couche obtenue après l’interpolation afin de couvrir l’intégralité du processus d’analyse.
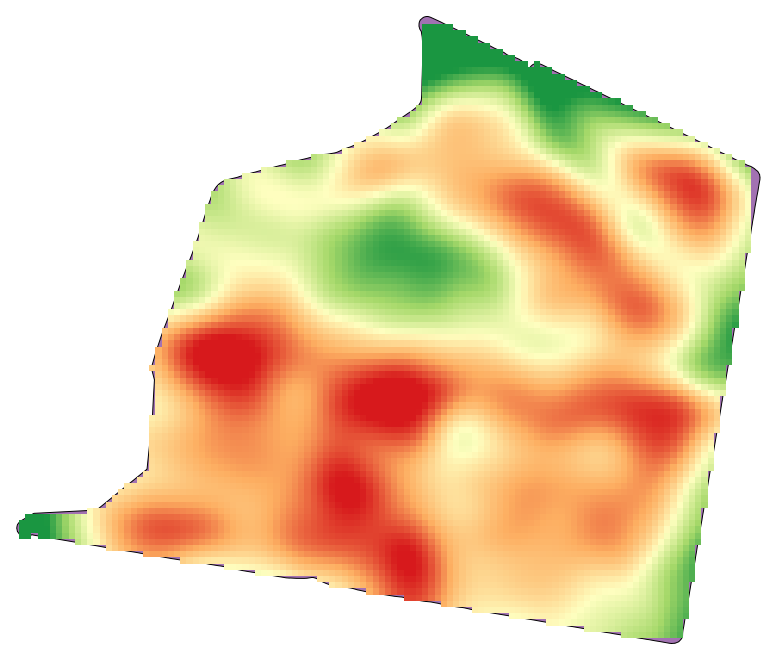
Ouvrez les données de l’exemple fourni pour cette leçon. Cela devrait ressembler à cela :

Ces données correspondent à des rendements agricoles tels qu’une moissonneuse moderne peut fournir, et nous les utiliserons afin d’obtenir une couche raster. Nous ne prévoyons pas d’analyser cette couche davantage par la suite. Nous allons juste l’utiliser comme fond de plan afin d’identifier facilement les zones les plus productives et celles où la production pourrait être optimisée.
La première chose à faire est de nettoyer la couche car certains points sont redondants. Cela est dû à la conduite de la moissonneuse : pour une raison ou une autre elle a dû tourner ou changer de vitesse à certains endroits. L’algorithme Filtrer points sera utile pour ceci. Nous l’utiliserons deux fois afin de supprimer à la fois les points qui peuvent être considérés comme aberrants car sortant de la norme par le haut ou par le bas.
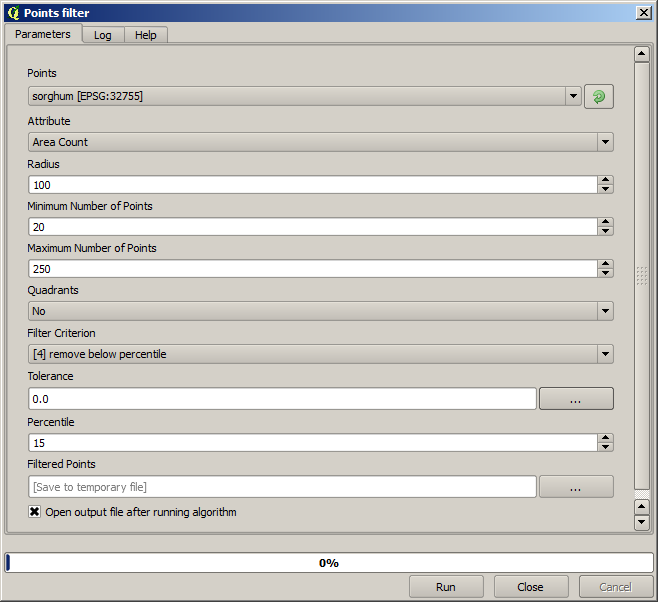
Pour la première exécution, utilisez les valeurs suivantes des paramètres.
Pour le second filtrage, utilisez les paramètres suivants :
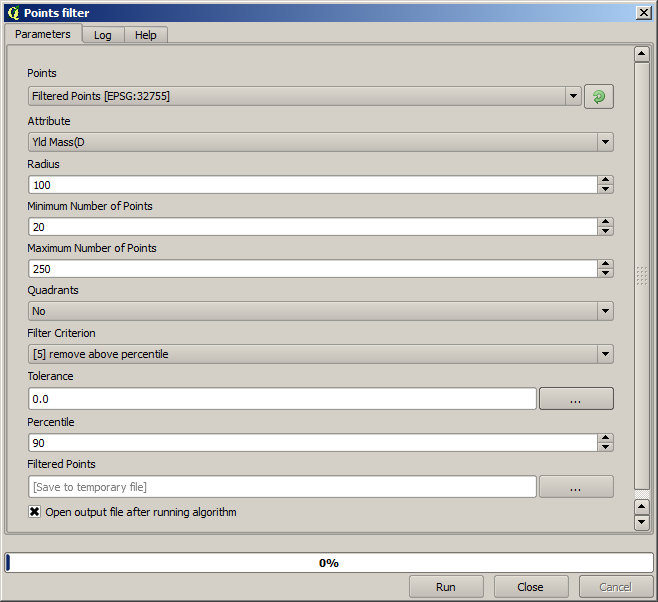
Notez que vous n’utilisez pas la couche de départ comme entrée, mais la sortie de la précédente itération.
La couche « filtrée » finale devrait ressembler à la couche originelle avec pour seule différence un nombre réduit de points. Vous pouvez vérifier cela en comparant leurs tables d’attributs.
Transformons maintenant la couche en raster au moyen de l’algorithme « rasterize ».
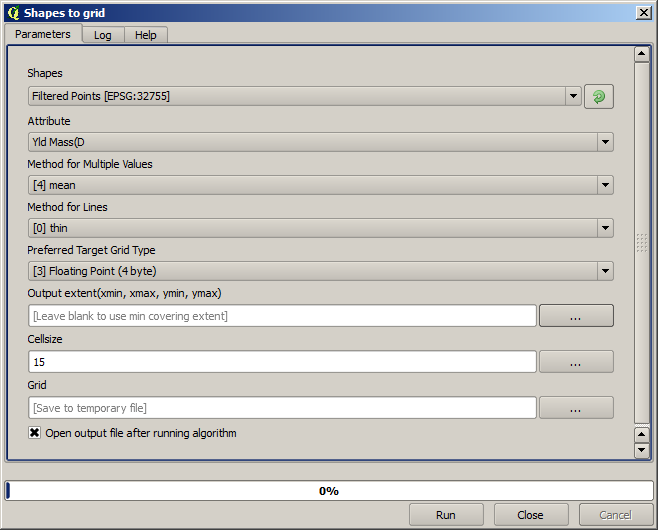
La couche Filtered points réfère à celle résultant de l’application du second filtre. Attention, étant donné que le nom est assigné par l’algorithme, elle a le même nom que celle produite suite à l’application du premier filtre. Il faut utiliser la seconde couche produite. Afin d’éviter toute confusion et étant donné que nous n’allons pas utiliser la première couche produite, vous pouvez la supprimer de votre projet et ne garder que la dernière couche.
La couche raster résultante devrait ressembler à ceci :

Il s’agit déjà une couche raster, mais certaines de ses cellules manquent de données. Elle ne contient des données que dans les cellules où se trouvait un point. Toutes les autres cellules ont été attribuées la valeur « pas de donnée ». Afin de compléter les valeurs manquantes, nous pouvons utiliser l’algorithme Close gaps.
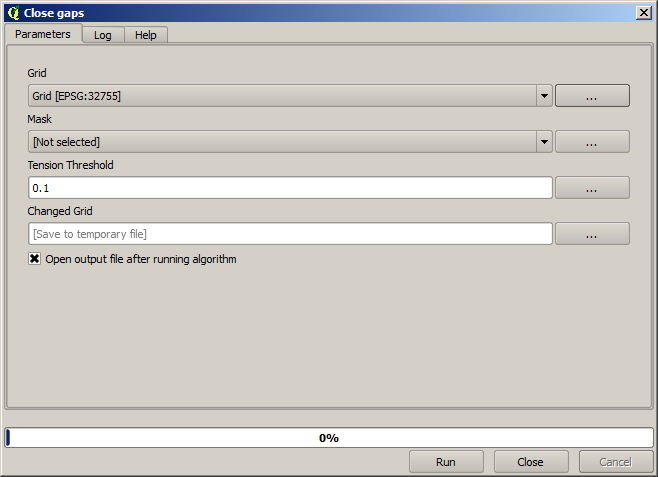
La couche complétée ressemble à ceci :

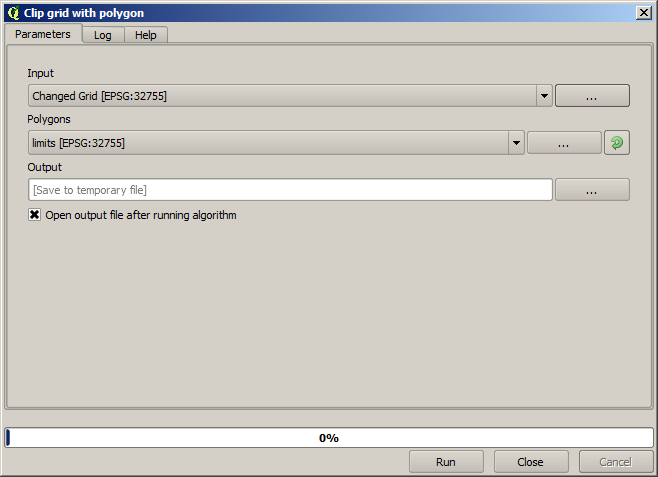
Afin de restreindre la couche uniquement à la zone où les rendements agricoles ont été effectivement mesurés, nous pouvons ne garder de la couche raster que ce qui correspond à la couche « limits » fournie.
Et pour un résultat plus lissé (moins précis mais plus adéquat pour être utilisé comme couche de fond) nous pouvons y appliquer un filtre Gaussien.
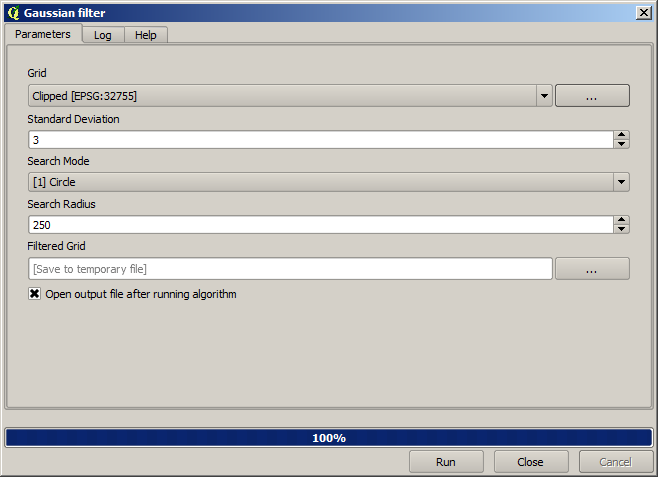
Avec les paramètres précédents, vous obtiendrez le résultat suivant :