Important
La traduction est le fruit d’un effort communautaire auquel vous pouvez vous joindre. Cette page est actuellement traduite à 89.77%.
15.1. Leçon : Introduction aux bases de données
Avant d’utiliser PostgreSQL, assurons-nous de consolider nos fondations en abordant la théorie générale de bases de données. Vous n’aurez besoin d’entrer aucun des codes en exemple; ils ne servent qu’à des fins d’illustration.
Objectif de cette leçon: Comprendre les concepts fondamentaux des Bases de Données
15.1.1. Qu’est-ce qu’une Base de Données?
Une base de données consiste en un ensemble organisé de données destinées à une ou plusieurs utilisations, généralement sous format numérique. - Wikipedia
Un Système de Gestion de Base de Données (SGBD) se compose d’un logiciel qui exploite des bases de données, gère le stockage, l’accès, la sécurité, la sauvegarde/restauration et autres fonctionnalités. - Wikipedia
15.1.2. Tables
Dans les bases de données relationnelles et à plat, une table est un jeu de données (valeurs) qui est organisé en utilisant un modèle de colonnes verticales (qui sont identifiées par leur nom) et de lignes horizontales. Une table contient un nombre spécifique de colonnes mais elle peut avoir autant de lignes qu’il faut. Chaque ligne est identifiée par des valeurs qui apparaissent dans un colonne particulière qui est identifiée comme une clef. - Wikipedia
id | name | age
----+-------+-----
1 | Tim | 20
2 | Horst | 88
(2 rows)
Dans une base de données SQL, une table est aussi appelée relation.
15.1.3. Colonnes / Champs
Une colonne est un jeu de valeur d’un type particulier, pour une valeur par ligne. Les colonnes fournissent la structure qui permet de composer les lignes. Le terme champ est souvent utilisé pour nommer la colonne même si certains considère qu’il est plus correct d’employer le mot champ (ou valeur de champ) pour se référer à un élément spécifique qui est présent à l’intersection entre une ligne et une colonne. - Wikipedia
Une colonne :
| name |
+-------+
| Tim |
| Horst |
Un champ :
| Horst |
15.1.4. Enregistrements
Un enregistrement est une information stockée dans une ligne d’une table. Chaque enregistrement aura un champ pour chacune des colonnes de la table.
2 | Horst | 88 <-- one record
15.1.5. Types de Données
Les Types de données restreignent le genre d’informations pouvant être stockées dans une colonne. - Tim and Horst
Il existe différents type de données. Voyons les plus fréquents:
“String” - pour stocker des données de texte libre
“Integer” - pour stocker des nombres entiers
“Real” - pour stocker les nombres décimaux
Date- pour stocker l’anniversaire de Horst afin que personne n’oublie“Booléen” - pour stocker des valeurs vrai/faux
Dans une base de données, vous pouvez autoriser de ne rien stocker dans un champ. S’il n’y a rien dans un champ, alors le contenu de ce champ est référencé comme une valeur “null”:
insert into person (age) values (40);
select * from person;
Résultat:
id | name | age
---+-------+-----
1 | Tim | 20
2 | Horst | 88
4 | | 40 <-- null for name
(3 rows)
Beaucoup d’autres types de donnée peuvent être utilisés, référez-vous au manuel de PostgreSQL !
15.1.6. Modéliser une base de données adresse
Etudions un cas simple pour voir comment est construite une base de données. Nous allons créer une base de données adresse.
★☆☆ Essayez vous-même
Ecrivez les propriétés qui composent une adresse et que vous voulez stocker dans la base.
Réponse
For our theoretical address table, we might want to store the following properties:
House Number
Street Name
Suburb Name
City Name
Postcode
Country
When creating the table to represent an address object, we would create columns to represent each of these properties and we would name them with SQL-compliant and possibly shortened names:
house_number
street_name
suburb
city
postcode
country
Structure d’une adresse
Les propriétés qui décrivent une adresse sont les colonnes. Le type d’information stockée dans chaque colonne est un type de données. Dans la section qui suit, nous analyserons notre table d’adresse pour voir comment l’améliorer !
15.1.7. Théorie de base de données
Le processus de création d’une base de données implique la création d’un modèle basé sur le monde réel: prendre les concepts du monde réel et les représenter dans une base de données en tant qu’entités.
15.1.8. Normalisation
Une des idées principales dans une base de données consiste à éviter la duplication/redondance de données. Le processus de suppression de la redondance dans une base de données s’appelle Normalisation.
La normalisation est une méthode systémique qui permet de s’assurer que la structure de base de données est adaptée aux requêtes génériques et qu’elle est débarassée de certaines caractéristiques non désirées liées aux anomalies lors d’insertion, de mise à jour ou de suppression qui peuvent engendrer une perte d’intégrité des données. - Wikipedia
Il existe différents types de normalisation.
Examinons cet exemple tout simple:
Table "public.people"
Column | Type | Modifiers
----------+------------------------+------------------------------------
id | integer | not null default
| | nextval('people_id_seq'::regclass)
| |
name | character varying(50) |
address | character varying(200) | not null
phone_no | character varying |
Indexes:
"people_pkey" PRIMARY KEY, btree (id)
select * from people;
id | name | address | phone_no
---+---------------+-----------------------------+-------------
1 | Tim Sutton | 3 Buirski Plein, Swellendam | 071 123 123
2 | Horst Duester | 4 Avenue du Roix, Geneva | 072 121 122
(2 rows)
Imaginez que vous avez beaucoup d’amis avec le même nom de rue ou de ville. Chaque fois que ces données sont dupliquées, elles consomment de l’espace. Pire encore, si un nom de ville change, vous devrez effectuer beaucoup de travail pour mettre à jour votre base de données.
15.1.9. ★☆☆ Essayez vous-même
Reconstruisez la structure théorique de la table people ci-dessus pour réduire la duplication d’information et normaliser la structure de données.
Pour en savoir plus sur la normalisation des bases de données, lisez ceci
Réponse
The major problem with the people table is that there is a single address field which contains a person’s entire address. Thinking about our theoretical address table earlier in this lesson, we know that an address is made up of many different properties. By storing all these properties in one field, we make it much harder to update and query our data. We therefore need to split the address field into the various properties. This would give us a table which has the following structure:
id | name | house_no | street_name | city | phone_no
--+---------------+----------+----------------+------------+-----------------
1 | Tim Sutton | 3 | Buirski Plein | Swellendam | 071 123 123
2 | Horst Duester | 4 | Avenue du Roix | Geneva | 072 121 122
In the next section, you will learn about Foreign Key relationships which could be used in this example to further improve our database’s structure.
15.1.10. Index
Un index de base de données est un lot de données destiné à accélérer les opérations de recherche de données. - Wikipedia
Imaginez que vous lisez un bouquin et cherchez la définition d’un concept - et que le bouquin n’a pas d’index! Vous devrez lire le livre depuis le début et page après page jusqu’à ce que vous trouviez l’information recherchée. L’index à la fin du livre vous permet d’aller directement à la page contenant l’information pertinente.
create index person_name_idx on people (name);
Maintenant, les recherches sur le nom seront plus rapides:
Table "public.people"
Column | Type | Modifiers
----------+------------------------+-------------------------------------
id | integer | not null default
| | nextval('people_id_seq'::regclass)
| |
name | character varying(50) |
address | character varying(200) | not null
phone_no | character varying |
Indexes:
"people_pkey" PRIMARY KEY, btree (id)
"person_name_idx" btree (name)
15.1.11. Séquences
Une séquence est un générateur de nombre unique. Il est normalement utilisé pour créer un identifiant unique pour une colonne d’une table.
Dans cet exemple, id est une séquence - le nombre est incrémenté chaque fois qu’un nouvel enregistrement est ajouté à la table :
id | name | address | phone_no
---+--------------+-----------------------------+-------------
1 | Tim Sutton | 3 Buirski Plein, Swellendam | 071 123 123
2 | Horst Duster | 4 Avenue du Roix, Geneva | 072 121 122
15.1.12. Diagramme Entité-Relation
Dans une base de données normalisée, vous disposez de plusieurs relations (tables). Le diagramme entités-association (ERD) est utilisé pour définir les dépendances logiques entre les relations. Voici notre modèle non normalisé de la table people de notre leçon précédente:
select * from people;
id | name | address | phone_no
----+--------------+-----------------------------+-------------
1 | Tim Sutton | 3 Buirski Plein, Swellendam | 071 123 123
2 | Horst Duster | 4 Avenue du Roix, Geneva | 072 121 122
(2 rows)
Avec un peu d’effort, nous pouvons la séparer en deux tables en supprimant le besoin de répéter le nom de la rue pour les individus qui vivent dans la même rue.
select * from streets;
id | name
----+--------------
1 | Plein Street
(1 row)
et :
select * from people;
id | name | house_no | street_id | phone_no
----+--------------+----------+-----------+-------------
1 | Horst Duster | 4 | 1 | 072 121 122
(1 row)
Nous pouvons ensuite lier les deux tables en utilisant les clefs “keys” streets.id et people.streets_id.
Si nous dessinons un Diagramme entité-association pour ces tables, il devrait ressembler à ce qui suit:

Le diagramme entité-association nous aide à exprimer les relations “un à plusieurs”. Dans ce cas, le symbole de flèche nous montre qu’une rue peut avoir plusieurs personnes qui vivent dedans.
★★☆ Essayez vous-même
Notre modèle de table people a encore des problèmes de normalisation. Essayez de les identifier et de les corriger à l’aide d’un diagramme entité-association.
Réponse
Our people table currently looks like this:
id | name | house_no | street_id | phone_no
---+--------------+----------+-----------+-------------
1 | Horst Duster | 4 | 1 | 072 121 122
The street_id column represents a “one to many” relationship between the people object and the related street object, which is in the streets table.
One way to further normalise the table is to split the name field into first_name and last_name:
id | first_name | last_name | house_no | street_id | phone_no
---+------------+------------+----------+-----------+------------
1 | Horst | Duster | 4 | 1 | 072 121 122
We can also create separate tables for the town or city name and country, linking them to our people table via “one to many” relationships:
id | first_name | last_name | house_no | street_id | town_id | country_id
---+------------+-----------+----------+-----------+---------+------------
1 | Horst | Duster | 4 | 1 | 2 | 1
An ER Diagram to represent this would look like this:
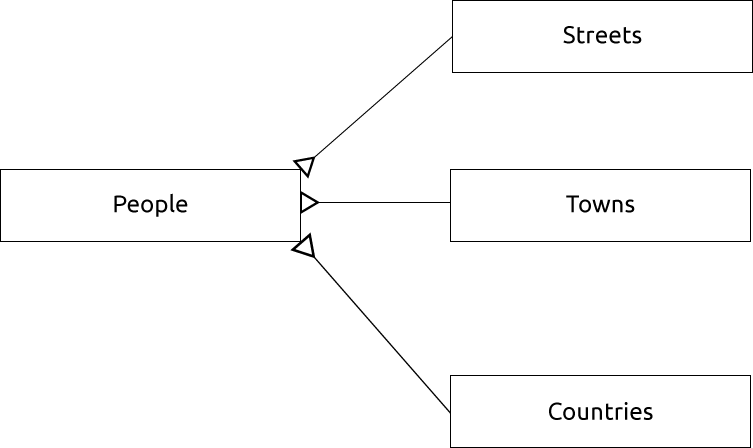
15.1.13. Contraintes, Clés Primaires et Clés Etrangères
Une contrainte de base de données est utilisée pour s’assurer que les données d’une relation correspondent à la vision du modélisateur sur le stockage de l’information. Par exemple, un contrainte sur le code postal permet de s’assurer que le nombre sera bien compris entre 1000 et 9999.
Une clef primaire est une ou plusieurs valeurs de champ qui identifie un enregistrement unique. En générale, la clef primaire est appelé identifiant et elle correspond à une séquence.
Une clef étrangère est utilisée pour se référer à un enregistrement unique d’une autre table (en utilisant la clef primaire de l’autre table).
Dans le diagramme entité-association, le lien entre les tables est basé sur la liaison entre les clefs étrangères et les clefs primaires.
Si vous regardez notre exemple sur les personnes, la définition de la table montre que la colonne “street” est une clef étrangère qui référence la clef primaire de la table des rues:
Table "public.people"
Column | Type | Modifiers
-----------+-----------------------+--------------------------------------
id | integer | not null default
| | nextval('people_id_seq'::regclass)
name | character varying(50) |
house_no | integer | not null
street_id | integer | not null
phone_no | character varying |
Indexes:
"people_pkey" PRIMARY KEY, btree (id)
Foreign-key constraints:
"people_street_id_fkey" FOREIGN KEY (street_id) REFERENCES streets(id)
15.1.14. Transactions
Lorsque vous ajoutez, modifiez ou supprimez une donnée dans une base de données, il est toujours important de laisser la base de données dans un état consistant si quelquechose tourne mal. La plupart des bases de données fournissent un mécanisme de transaction. Les transactions vous permettent de créer une position de retour sur laquelle on peut revenir si les modifications ne se sont pas déroulées comme prévu.
Prenons un scénario ou vous avez mis en place un système de comptabilité. Vous devez transférer des fonds d’un compte à l’autre. Les étapes se dérouleront de la manière suivante:
Supprimer R20 du compte Joe.
Ajouter R20 au compte Anne.
Si quelquechose se passe mal lors du processus (ex: une panne de courant), la transaction sera annulée.
15.1.15. Conclusion
Les bases de données vous permettent de gérer vos données de manière structurée en utilisant des structures de code simple.
15.1.16. La suite ?
Maintenant que nous avons jeté un coup d’oeil sur le fonctionnement des bases de données, créons une nouvelle base pour mettre en pratique ce que nous avons appris.